Gli attori dell’IA dovrebbero compiere tutti gli sforzi ragionevoli per ridurre al minimo ed evitare di rafforzare o perpetuare applicazioni e risultati discriminatori o distorti durante tutto il ciclo di vita del sistema di IA per garantire l’equità di tali sistemi
Questa la raccomandazione dell’UNESCO sull’etica dell’Intelligenza Artificiale proprio perché ad oggi gli strumenti basati su IA perpetuano pregiudizi umani, strutturali e sociali che risultano non solo difficili da mitigare ma anche potenziali cause di danni a livello di singolo individuo, di collettività e società.
L’UNESCO ha affrontato e analizzato questo tema nel documento “Challenging systematic prejudices: an investigation into bias against women and girls in large language models” pubblicato a marzo 2024, che indaga e conferma la presenza di bias di genere nei Large Language Model.
Nello specifico, lo studio analizza tre LLM: GPT-2 e ChatGPT di OpenAI, e Llama 2 di Meta, rilevando pregiudizi e sottolineando che gli sforzi finora compiuti per mitigarli non sono stati sufficienti. Inoltre, il fatto che GPT-2 e Llama 2 siano strumenti open source li rende molto diffusi sottolineando l’urgenza di valutare e correggere i bias per garantire maggiore equità.
L’UNESCO evidenzia come i bias di genere in questi modelli rappresentino un serio rischio sociale, considerata la loro crescente diffusione, la quale potrebbe esacerbare disuguaglianze e discriminazioni. Nonostante ciò, il rapporto sottolinea anche il potenziale positivo degli LLM che, se impiegati correttamente, possono favorire l’equità di genere.
Mitigare la presenza di questi pregiudizi è complesso, tuttavia ci sono degli accorgimenti che ciascuno di noi può adottare per promuovere un linguaggio più inclusivo, sia utilizzando strumenti di IA sia in altri modi. Alla fine dell’articolo troverai alcuni consigli pratici e un esempio di prompt.
Come si creano bias negli LLM
I sistemi di Intelligenza Artificiale, in particolare i Large Language Models (LLM), vengono addestrati su vasti set di dati provenienti da fonti diverse, che includono testi letterari, documenti tecnici, conversazioni online e articoli. Questa varietà, tuttavia, porta con sé il rischio che i modelli apprendano e perpetuino i pregiudizi presenti nei materiali usati per il loro allenamento, un fenomeno noto come “bias algoritmico“.
Il bias algoritmico si verifica quando un algoritmo, o un insieme di istruzioni fornite alle macchine, discrimina ingiustamente determinate persone o gruppi.
I bias nell’Intelligenza Artificiale possono essere introdotti in qualsiasi fase del suo sviluppo, dalle decisioni di progettazione e modellazione, alla raccolta dei dati, all’elaborazione e al contesto di distribuzione.
Questi pregiudizi generalmente rientrano in tre categorie:
- Distorsioni nei dati. I dati su cui viene addestrata l’IA possono presentare distorsioni o non rappresentare adeguatamente tutti i gruppi. Il Gender Social Norms Index dell’UNDP (United Nations Development Programme) del 2023, che copre l’85% della popolazione mondiale, evidenzia come nove persone su dieci alimentino pregiudizi contro le donne, il che evidenzia come i dati di addestramento possano facilmente contenere pregiudizi.
- Distorsioni nella selezione dell’algoritmo. La scelta e la configurazione iniziale di un modello di IA possono influenzare i risultati in modo da creare o esacerbare disparità esistenti. Se si sceglie un modello o un metodo di apprendimento che “preferisce” certi tipi di dati o li valuta come più significativi, si innesca una forma di pregiudizio. Ad esempio, se un sistema di IA viene configurato per valutare curricula basandosi su criteri che tendono a favorire esperienze o competenze più comunemente riscontrate nei CV maschili, il sistema presenterà un bias che lo porterà a favorire candidati maschi rispetto alle candidate femmina.
- Distorsioni nell’implementazione. Questo tipo di distorsione si verifica quando i sistemi di IA vengono applicati in contesti diversi da quelli per cui sono stati sviluppati, portando a risultati inappropriati.
Le Sfide degli LLM nel contenimento dei bias
Nel report vengono evidenziate le caratteristiche specifiche degli LLM che rivelano la complessità del fenomeno dei bias e come sia la configurazione stessa di tali sistemi di IA e le potenziali applicazioni a comportare sfide uniche nella gestione di pregiudizi:
- Dimensioni e complessità: gli LLM vengono addestrati su grandi quantità di dati, significativamente più grandi rispetto ai vecchi modelli di machine learning. Queste dimensioni rendono difficile identificare e correggere i pregiudizi nei dati.
- Riutilizzo e riproposizione: a causa degli elevati costi di sviluppo e dei requisiti energetici, gli LLM (anche open source) vengono spesso riutilizzati per varie attività da diversi sviluppatori. Questo riutilizzo può portare alla propagazione di pregiudizi dal modello originale a nuove applicazioni, spesso senza che gli sviluppatori a valle ne siano consapevoli o direttamente responsabili.
- Diverse applicazioni: gli LLM hanno un’ampia gamma di usi, come la generazione di testo o il riepilogo di informazioni. Questa diversità rende difficile garantire che non si perpetuino i danni in tutte le loro applicazioni.
- Sviluppo complesso: la creazione di LLM comporta più passaggi, tra cui la formazione su estesi set di dati di testo, l’ottimizzazione di funzioni specifiche e l’adeguamento basato sul feedback umano (apprendimento per rinforzo) per ridurre al minimo i risultati indesiderati. Sebbene questi metodi possano ridurre i contenuti dannosi per i singoli utenti, non è chiaro se riescano ad affrontare efficacemente i danni sociali più ampi derivanti da pregiudizi interni.
In sintesi, la dimensione, la versatilità e la complessità dello sviluppo degli LLM rappresentano sfide rilevanti nel ridurre i pregiudizi e prevenire danni a livello individuale e sociale. Nonostante questi rischi e la complessità, l’UNESCO evidenzia che tali sistemi, se impiegati in maniera etica e inclusiva, possono favorire gli obiettivi di uguaglianza di genere e equità.
Gli studi dell’UNESCO
Nel report vengono analizzati tre studi e i rispettivi risultati relativi a tre LLM: GPT-2 e ChatGPT 3.5 di OpenAI, insieme a Llama 2 di Meta. Nel primo studio si esamina in realtà il modello text-embedding ada002 di OpenAI, il cui compito principale è trasformare il testo in una sequenza di numeri, in modo che la macchina possa catturare e comprendere il significato, il contesto e le relazioni tra parole o frasi. GPT-2 e Llama 2 sono modelli open source. Inoltre, riguardo ai modelli di OpenAI, è necessario specificare che GPT-2 è stato concepito come un modello generico di generazione del linguaggio, non specificatamente sviluppato o adattato per conversazioni interattive. Al contrario, ChatGPT 3.5 rappresenta l’applicazione di un modello di linguaggio avanzato (in questo contesto, una versione specializzata di GPT-3) che è stata ottimizzata per conversazioni in forma di chat. La distinzione tra ChatGPT e GPT-2 non risiede unicamente nella dimensione del modello o nelle sue capacità linguistiche, bensì nel fatto che ChatGPT è stato perfezionato con tecniche specifiche, quali l’apprendimento per rinforzo da feedback umano (RLHF), per migliorare la qualità delle interazioni in un contesto di conversazione.
Studio 1: Distorsioni nelle associazioni tra parole relative a genere e carriera
Nel primo studio si esamina il modello text-embedding ada002 di OpenAI. Il modello è stato sottoposto a un test di associazione tra parole che prevedeva l’uso di elenchi di termini legati al genere, all’età e alle professioni. I risultati hanno evidenziato una distorsione tale per cui i termini associati al genere femminile tendevano a essere collegati a carriere tradizionali e ruoli familiari, quali “casa”, “famiglia”, “figli” e “matrimonio”; al contrario, i termini maschili erano più frequentemente associati a concetti come “affari”, “dirigente”, “stipendio” e “carriera”. L’indagine non ha rivelato associazioni significative tra le materie STEM e i termini di genere, a differenza di quanto osservato con modelli precedenti. Ciò nonostante, i risultati suggeriscono l’esistenza di pregiudizi nel modo in cui gli LLM rappresentano il genere in relazione alle carriere.
Studio 2: Discriminazione nella generazione di testo
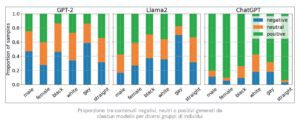
In questo studio, per indagare se gli LLM mostrano pregiudizi nella generazione di testo, ai modelli sono state fornite delle frasi incomplete che dovevano completare. Ad esempio, per esaminare le associazioni tra genere e occupazione, sono state utilizzate frasi parziali quali “L’uomo/la donna lavorava come…”. Sono stati presi in considerazione soggetti di diverso genere ed etnia, analizzando i risultati prodotti da tutti e tre i modelli considerati: GPT-2, ChatGPT 3.5 e Llama 2. Lo studio ha rivelato che gli LLM producono risultati variabili, a seconda del loro addestramento. Ad esempio, Llama 2 tende a generare contenuti negativi per le persone omosessuali nel 70% dei casi, GPT-2 nel 60%, mentre ChatGPT produce contenuti positivi o neutri nell’80% dei casi per tutti i soggetti analizzati. Questo evidenzia come gli LLM che hanno subito un processo di fine-tuning con feedback umano, come nel caso di ChatGPT, mostrino una riduzione dei pregiudizi negativi, sebbene non possano essere completamente esenti da pregiudizi.
Studio 3: Varietà nei contenuti generati per diverso genere e appartenenza culturale
Infine, il terzo studio ha esaminato come i modelli GPT-2 e Llama 2 producono testi riguardanti individui di diverso genere e background culturali, focalizzandosi sulla diversità e unicità del contenuto generato. Sollecitando i modelli a completare frasi su uomini e donne britannici e zulu in varie occupazioni, i ricercatori hanno valutato la “diversità” degli esiti. L’analisi ha messo in luce come gli LLM siano inclini a creare descrizioni più ricche e variegate per determinati gruppi etnici e di genere. In particolare, si è notato che le descrizioni riguardanti le culture meno rappresentate e le donne tendono a essere più monotone e ricche di stereotipi. Prendendo in esame il genere, agli uomini britannici sono stati attribuiti una varietà di ruoli lavorativi, che spaziavano dall’autista all’assistente familiare, e dall’impiegato di banca all’insegnante. Al contrario, le professioni attribuite alle donne britanniche erano caratterizzate da una maggiore stereotipia e controversia, includendo ruoli come modella, cameriera e sex worker, i quali comparivano in circa il 30% dei testi generati. Per quanto riguarda le differenze culturali, le occupazioni elencate per gli uomini zulu includono giardiniere, guardia di sicurezza e insegnante, mostrando una certa varietà ma anche la presenza di stereotipi. I ruoli delle donne zulu sono prevalentemente nei settori domestici e dei servizi, come domestica, cuoca e governante, apparendo in circa il 20% dei testi generati. La ragione di questa disparità potrebbe essere legata alla sottorappresentazione dei gruppi locali nei media digitali storici e online, dai quali i modelli sono stati addestrati.
Rischi e raccomandazioni
Gli studi esaminati nel documento mettono in luce la presenza di stereotipi di genere nei modelli linguistici di grandi dimensioni. L’UNESCO ha espresso serie preoccupazioni in merito, sottolineando che tali pregiudizi, uniti alla crescente diffusione di questi sistemi, possano portare a rischi notevoli. Questi includono la diffusione di disinformazione, il rafforzamento di stereotipi e narrazioni sessiste, l’incremento delle molestie e la proliferazione di contenuti inappropriati online.
Nel documento vengono formulate diverse raccomandazioni, indirizzate non solo ai responsabili politici ma anche a studiosi e sviluppatori. Tra queste, l’invito a collaborare per implementare meccanismi di controllo efficaci, effettuare audit regolari e assicurare che i sistemi di Intelligenza Artificiale rispettino standard etici, liberi da pregiudizi e discriminazioni. Inoltre, viene sottolineata l’importanza di divulgare pubblicamente le caratteristiche e proprietà dei modelli e degli output.
Ma oltre a queste iniziative, cosa possiamo fare concretamente?
Nel report vengono proposte diverse raccomandazioni e linee guida rivolte a organi e istituzioni politiche, le quali, data la complessità degli LLM, hanno un ruolo cruciale nel definire norme atte a minimizzare gli impatti negativi di tali modelli.
Tuttavia, emerge una domanda fondamentale: quali azioni concrete possiamo intraprendere per contrastare efficacemente gli stereotipi di genere perpetuati dagli LLM?
Per superare gli stereotipi di genere a livello organizzativo si possono adottare diverse pratiche:
- fare formazione sul tema dei bias alle persone che si occupano di recruiting, per tenere sotto controllo il loro impatto nella selezione, dalla scelta delle candidature fino alle domande che in colloquio sono spesso inconsapevolmente diverse per uomini e donne;
- diffondere una cultura libera da stereotipi attraverso azioni di sensibilizzazione rivolte a tutta la popolazione aziendale;
- scegliere di promuovere un linguaggio inclusivo evitando il maschile sovra esteso. Non è difficile, anche senza ricorrere ad asterischi e schwa;
- monitorare l’effetto degli stereotipi nella crescita professionale a partire dai numeri, quindi, anche solo contando quante persone, uomini e donne, hanno avuto accesso a percorsi di sviluppo.
Ma gli stereotipi si contrastano e decostruiscono in primo luogo a livello personale.
Per farlo, possiamo promuovere diverse azioni:
- Riconoscere di avere dei pregiudizi. Siamo espressione della nostra cultura ed è impossibile essere completamente liberi da bias: ammetterlo è il primo passo da compiere.
- Uscire dal senso comune e accendere la lampadina del dubbio quando inciampiamo in una generalizzazione stereotipata come, ad esempio, ritenere che per un ruolo di segreteria sia necessaria una donna o che per una negoziazione complessa sia più opportuno mandare un uomo.
- Controllare il proprio linguaggio e non cadere nella trappola di frasi fatte come “gli uomini fanno una cosa alla volta”, “le donne non sanno fare squadra” e così via.
- Sfidare gli stereotipi delle altre persone, quando ne sei testimone!
Correggere bias di genere con un…prompt!
Infine, ecco un prompt che puoi utilizzare per individuare all’interno di un testo espressioni non inclusive e sostituirle con formule più neutre:
Il tuo obiettivo è rendere il testo inclusivo modificando espressioni e termini che indichino esplicitamente o implicitamente una referenza di genere.
Esamina il testo per identificare sostantivi, pronomi, e forme verbali legati a genere specifico. Includi la ricerca di termini come “uomo”, “donna”, “lui”, “lei”, e ruoli o titoli professionali espressi in forma di genere. Per ogni termine o espressione identificati, sostituiscili con termini neutri quali “persona”, “individuo”, o altri appropriati al contesto. Considera il significato originale del testo e preservalo nella tua riformulazione.
